Relationships between records in Heurist build dependencies between these records. Dependencies are an important concept, not only for creating an efficient structure for a Heurist database, but also for managing CSV file imports. The use of the term “dependency” in Heurist is similar to the use of the term in computer science meaning a situation where a statement in a program refers to another statement. We can therefore also use the term “linkages” for dependencies. Relationships between records set up linkages between these records. It is a “dependency”, because in order for each specific link to exist, the records become dependent on each other – obviously, you cannot link records which do not exist. Thus, two records become dependent on one another because of the relationship between them.

Records can be linked in Heurist in a number of different ways. These linkages can also be hierarchical – with one linkage referencing a record, which is itself linked to other records – forming a web of linkages. Heurist contains visualisation tools, such as Network Diagram (in the Filter-Analyse-Publish screen) which can help us to see the linkages between records in our database. In the screenshot shown above, the records from the Shakespeare play, “Macbeth’, are shown with some of their linkages. Single arrows reflect records linked by Pointer fields and double arrows reflect records linked by Relationship Marker fields.

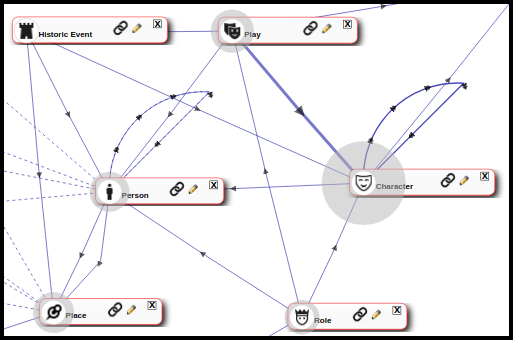
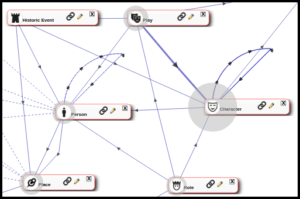
The Visualise tool in the Manage screen can also help us to understand the linkages formed by the structure of the record types in our database. In the screenshot shown above, some of the record types associated with Shakespearean plays are shown as a web of linkages. You can see that some record types link back to themselves (for example, a Person record can be related to another Person record – “ChildOf” etc. Characters can also be related to each other in similar ways). These visualisation tools help to conceptualise the dependencies that exist within a Heurist database.
Dependencies mainly become important during the process of importing CSV files. During the import process, one is asked to define the primary record type. This is the main record type for which you are importing data. Once one has selected the primary record type, one is asked to define any dependencies that may be present in the data for this import file. Note, that the selection of dependencies is specific for each import file. One can not import dependencies for which one has no data, similarly, if you fail to select a dependency for which there is data, Heurist will have no way of matching that data.
Importing Dependencies
Let us consider this with a specific example. Let us suppose that we are importing a table of data on Shakespeare’s plays into the database shown in these examples above. We have information in a spreadsheet detailing aspects about each play and we have exported this to a CSV file. Since we are importing into the Play record type, we need to consider the dependencies which may be present related to the Play record type. If we consider the Visualise diagram above, we can see that Play has possible linkages (dependencies in the case of an import) to the Character, Person, Role, Mythological Element and Historic Event record types. If our dataset includes the names of Plays and Characters in the Plays, then we will add Characters as a dependency of Play. In fact, in the example given here, Character is a child record of Play, thus it is critical that we add the Characters as dependencies of Play records, so that we don’t create orphans. For the sake of clarity, and being able to easily correct errors in the original dataset during the import process, we strongly recommend that large datasets are subdivided into smaller CSV files. It is preferable to deal with one dependency (or group of dependencies) at a time. This is also necessary since there may be more than one potential match to Heurist record types in the original dataset.
For example, one might have a column in a spreadsheet that has the names of Persons as the Playwright, and another that has the names of Persons as Actors playing Characters. If these are imported at the same time, Heurist will not be able to differentiate which Persons should populate the Playwright field and which should populate the Actor field. It is therefore best to split this into (at least) 2 distinct files – one of which populates the Playwright field and another of which populates the Actor field. Below is an example of data to populate the Play – Playwright section. Note that here the Person record (which will populate the Playwright field) is a dependency on the Play record. We can make it even more complicated by having data on Place of Birth. The Place of Birth field points to a Place record, and thus we have a hierarchy of dependencies: Place is a dependency of Person, which in turn is a dependency of Play. Whilst none of this data is a Required field, in order to populate the Person and Place pointer fields, it is required that we import data for those fields – thus making the fields into dependencies for this particular import. Note that in order to record multiple plays by the same playwright, the information for playwright is repeated in each row (see CSV data in the background of the screenshot).

In the example shown in the screenshot above, you can see both the contents of the CSV file in the background on the left and the dependencies selected in the popup. Our Primary record type in this example is Play, because we want to add new Play records and populate the “Playwright” pointer field in the Play records. Note that Playwright pointing to Person is the first listed dependency under the Play record type. On the righthand side of the popup you can see that the pointer Playwright to Person has a Heurist ID, which is written in a greenish yellow font: Playwright H-ID. Looking down the list of dependencies, we can see that the Playwright to Person pointer is listed as the fourth dependency (after Characters, Historic Events and Place). Therefore we check the box next to the Playwright to Person dependency. Playwright to Person itself has further dependencies (pointers or linked records). The dependencies relate to fields in the Person record type. These fields are Life Events, Associated Person, Place of birth and Place of death. In our example we have data to populate the Place of birth field in the Person record. Note that the Place of birth field is a pointer to a Place record. It has its own Heurist ID (Place(s) H-ID). Since we wish to populate this field, we need to select the dependency to do so. Thus we look further down the list to find the Place(s) pointer to Place and check the box. We choose this dependency rather than the Place pointer to Place listed above Playwright because on examination of the Heurist IDs on the right, we can see that Place (without the (s) added) is a pointer from Historic Event and will record the Place associated with the Historic Event. We do not wish to record any places associated with historic events, so we have to rather choose the dependency associated with Place of birth, which is Place(s).
Since we do not want to import any other information at this time, we do not check any other dependencies. This is also very important. If we select any other dependencies, we must have data to populate those fields in our current CSV file. We will not be able to proceed if that information is missing. Therefore, we choose only the dependencies in the data in the current CSV file being imported, and no others.

Heurist will now start at the most fundamental point in the hierarchy of dependencies to import data. The first dependency to to imported will therefore be the Place(s) records for Place of birth. These records are a dependency of Person which in turn is a dependency of Play, so Place(s) needs to be imported so that Person can be imported, so that Play can be populated. Heurist will import data for each of the dependent records in turn, before creating the linkages between all these records (obviously, it cannot do this the other way round). We will therefore be asked to match and then import our Place of birth records first (see screenshot above). Secondly, we will be asked to match and import our Person records to populate the Playwright fields. We will import both Family Name and Given Names for the Person records. In this case, William Shakespeare with a birthplace of Stratford Upon Avon is already a record in the database, so Heurist will match the record and proceed immediately to Play without any import being necessary. Otherwise we would import the fields for Person, including the pointer field to Place of birth. We now match our Play records to the Title of Play field. In this example we have 3 new Play records which will be added to the database.

Once we have matched the Play records, we now need to populate the fields of the Play record type and this includes our pointer to Playwright (see above). This will create the links between the Person record and the Play record, through the Playwright field, as well as populating 3 new Plays into the database (all with the same Playwright, in this case). The process would be the same if we were dealing with different Plays by different Playwrights, since it is matching the previously imported “Playwright H-ID” records to the Playwright record pointer field. Once we have run the Insert/Update, we will have 3 new Play records in our database, each of which points to the Person record, William Shakespeare, as the Playwright (see below).

Now, let us presuppose that our dataset also includes People who have acted in certain Roles as particular Characters in particular Plays. We don’t import that data at the same time as the Playwright data, otherwise Heurist can’t distinguish which Person records are Actors and which Person records are Playwrights. Therefore, it is best to create a second CSV file, which contains the Actor and Roles information. This time our Primary record type will be Role, not Play. There is no pointer from Play to Actors and Roles, rather the Role record type points back to Play, as well as to Persons as Actors, Directors etc and to the Characters played (where appropriate).

Note that when we choose Role as the primary record type, Person is a Required field and therefore the dependency Person below is automatically checked. We will also check the dependencies for Play, Characters and Place(s) for Place of Birth. In this example, Play is the most fundamental record type and therefore it gets imported first. Heurist builds the order for import as first Play, then Place(s), then Person, then Character, then Role (see screenshot below).

Once Place(s) is defined, we can subsequently populate the record pointer for Place of birth in the Person record. Once Play, Person and Character are defined we can then populate the relevant fields in Role.Thus each of these records is dependency of the records which point to them and need to be imported or matched before the final linkages are made. The results of the import process are displayed in the screenshot below. Compare this to the CSV data which was imported, which can be seen in the background of the image of the checked dependencies shown higher up this page. In this screenshot we have opened each of the individual records (highlighted in blue in the Record View screen) – viz. Play, Person (with Place of birth – Waterford, Ireland, in this example) and Character. The web of linked records is clearly indicated by the blue highlighted fields in each of these records – for example, there are links to all the people who have played the role of Macbeth, from the Character Macbeth; there are links to all the Characters from the Play, Macbeth. The advantages of these linked records for facilitating analysis and management is readily apparent.

Whilst Heurist can easily manage the systematic import of complex dependencies, we strongly advise that you simplify this process by subdividing your data into smaller files for import. As can be seen by the example above, the complexity and hierarchy of dependencies can grow quickly and thus, to ensure that the process achieves the results desired, it is best to ensure that you understand the structure of the data being imported.
Creation of Linkages
It is also critical that the import process is completed. If the import process is aborted halfway through the process, then whichever records have been imported to that point will exist in the database, however, the final linkages to the primary record type will not have been made, as this happens in the final step of the import process, once the records for linking are complete. This can lead to records which are meant to be linked to other records, but instead float in isolation. If you need to abort the import process in order to fix up something in either the CSV file or the structure of the record types, do ensure that you return to the import to complete the process (the import wizard will return you to the point at which you aborted the process).